现在有一种类似树的数据结构,但是不存在共同的根节点 root,每一个节点的结构为 {key: 'one', value: '1', children: [...]},都包含 key 和 value,如果存在 children 则内部会存在 n 个和此结构相同的节点,现模拟数据如下图:
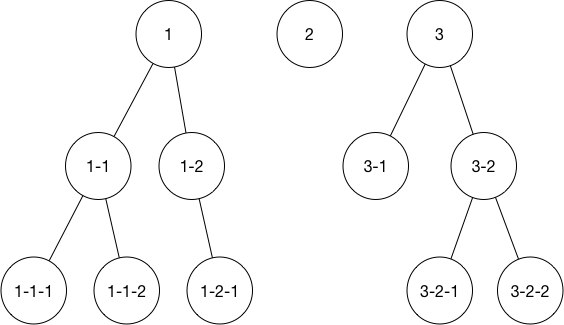
已知一个 value 如 3-2-1,需要取出该路径上的所有 key,即期望得到 ['three', 'three-two', 'three-two-one']。
广度优先遍历
广度优先的算法如下图:
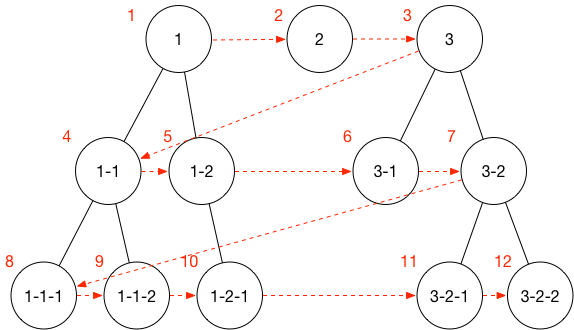
从上图可以轻易看出广度优先即是按照数据结构的层次一层层遍历搜索。首先需要把外层的数据结构放入一个待搜索的队列(Queue)中,进而对这个队列进行遍历,当正在遍历的节点存在子节点(children)时则把此子节点下所有节点放入待搜索队列的末端。因为本需求需要记录路径,因此还需要对这些数据做一些特殊处理,此处采用了为这些节点增加 parent 即来源的方法。对此队列依次搜索直至找到目标节点时,可通过深度遍历此节点的 parent 从而获得到整个目标路径。具体代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
function findPathBFS(source, goal) {
var dataSource = JSON.parse(JSON.stringify(source))
var res = []
res.push(...dataSource)
for (var i = 0; i < res.length; i++) {
var curData = res[i]
if (curData.value === goal) {
var result = []
return (function findParent(data) {
result.unshift(data.key)
if (data.parent) return findParent(data.parent)
return result
})(curData)
}
if (curData.children) {
res.push(...curData.children.map(d => {
d.parent = curData
return d
}))
}
}
return []
}
|
深度优先遍历
深度优先的算法如下图:
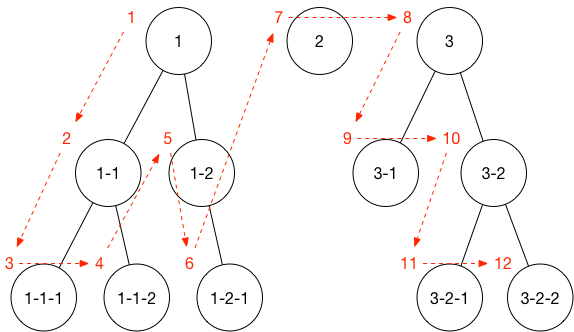
深度优先即是取得要遍历的节点时如果发现有子节点(children) 时,则不断的深度遍历,并把这些节点放入一个待搜索的栈(Stack)中,直到最后一个没有子节点的节点时,开始对栈进行搜索。后进先出(下列代码中使用了 push 方法入栈,因此需使用 pop 方法出栈),如果没有匹配到,则删掉此节点,同时删掉父节点中的自身,不断重复遍历直到匹配为止。注意,常规的深度优先并不会破坏原始数据结构,而是采用 isVisited 或者颜色标记法进行表示,原理相同,此处简单粗暴做了删除处理。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
function findPathDFS(source, goal) {
var dataSource = [{children: JSON.parse(JSON.stringify(source))}]
var res = []
return (function dfs(data) {
if (!data.length) return res
res.push(data[0])
if (data[0].children) return dfs(data[0].children)
if (res[res.length - 1].value === goal) {
res.shift()
return res.map(r => r.key)
}
res.pop()
if (!res.length) return res
var lastNode = res[res.length - 1]
lastNode.children.shift()
if (!lastNode.children.length) {
delete lastNode.children
return dfs([res.pop()])
}
return dfs(lastNode.children)
})(dataSource)
}
|
该方法在思考时,添加了根节点以把数据转换成树,并在做深度遍历时传入了子节点数组 children 作为参数,其实多有不便,于是优化后的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
function findPathDFS(source, goal) {
var dataSource = JSON.parse(JSON.stringify(source))
var res = []
return (function dfs(data) {
res.push(data)
if (data.children) return dfs(data.children[0])
if (res[res.length - 1].value === goal) {
return res.map(r => r.key)
}
res.pop()
if (!res.length) return !!dataSource.length ? dfs(dataSource.shift()) : res
var lastNode = res[res.length - 1]
lastNode.children.shift()
if (!lastNode.children.length) {
delete lastNode.children
return dfs(res.pop())
}
return dfs(lastNode.children[0])
})(dataSource.shift())
}
|
改进后的方法只关心传入的节点,如果存在子节点则内部自行处理,而非预先传入所有子节点数组进行处理,此方法更易理解一些。
结语
以上便是广度与深度遍历在 JS 中的应用,代码可在 codepen 中查看。